Demo page
Introduction
This plugin allows you to read and extract the text from images within your bubble application - no external API is required!
This Plugin uses the tesseract.js library License Apache 2.0 (no changes to the original code): https://github.com/naptha/tesseract.js/blob/master/LICENSE.md
Features
- Supported image formats: png, jpg, bmp, pbm
- Support for most languages.
How to Setup
Drag the OCR element onto your page.
You now have access to the "image to text" action. Simply provide the image that should be analyzed and the language code (https://tesseract-ocr.github.io/tessdoc/Data-Files#data-files-for-version-400-november-29-2016)
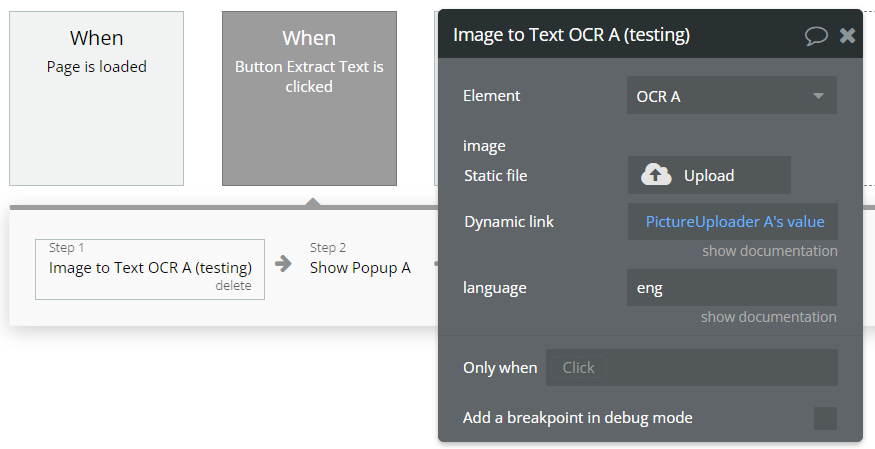
Depending on the amount of text, the scan can take some time. Once done, an event is triggered which you can use to trigger subsequent workflows.
You have access to the returned text via the elements state.
Frequently Asked Questions
Have a question, or suggestion, or encountered an issue? 🤷♂️
Please contact us by sending a mail to: support@rapidevelopers.com
Want to report a bug? Please follow this guideline!